F23: Week 15—People Names
- Casey Wolf

- Dec 7, 2023
- 3 min read
With Place Names finished last week, I then moved on to People Names to finish the Standard List. Given the potential alternatives in name spelling, the process of rectifying these variations to create standardized iterations proved more intensive. Additionally, it required a process of checking the names against an extensive list of collected sources and scholarship. With the goal of identifying individuals for other researchers and across other digital projects, choosing the most likely spelling is important to best connect the correct individual to larger scholarship networks.
Like with the Place Name sheet, the People Names sheet was only populated with a fraction of the terms it is meant to contain with the rest in the Key Words sheet. My first passthrough of the data involved a process of color coding and cross-referencing line numbers with potential matches. To populate the People Names sheet, I began by confirming potential matches across lines. I cross-checked variations by searching letter metadata to locate appearances within the letters. If references shared acquaintance networks, discussed associated topics, or engaged in related behavior across similar places, I assumed these instances referred to the same person. Moving down the list, I determined the “correct” individual, encoded the alternate spelling and any associated places in dedicated columns associated with the determined standard, and then deleted the cross-reference column numbers to confirm the decision. [Figure 1] Partially operating on assumption, this method remains imperfect, but it is one of the best ways to effectively process name data while still adhering to project requirements and deliverables.


Filling gaps in knowledge proved more difficult as many names cannot be fully known—most commonly due to illegibility or abbreviation without any further expansion or other mentions in the letters. Often, correspondents did not fully write out first names, leaving many terms incomplete with only an initial for the first name. For full names, determining the “correct” spelling involved cross checking terms against both historical and modern sources. One of the best historical sources for determining names is Joseph Besse's multivolume work A Collection of the Sufferings of the People Called Quakers...in the Year 1689. [Figure 2] Modern sources produced by genealogists and historical societies, particularly of Bucks County where many of the letter correspondents immigrated, provided a basis for the most commonly used spellings of Quaker surnames in the area. Passenger lists for incoming ships and land records have proved useful as well. Some names even appear as name authorities in other linked open data projects such as Wikidata and Virtual International Authority Files (VIAF)—thus, better connecting our dataset with larger networks of scholarship.
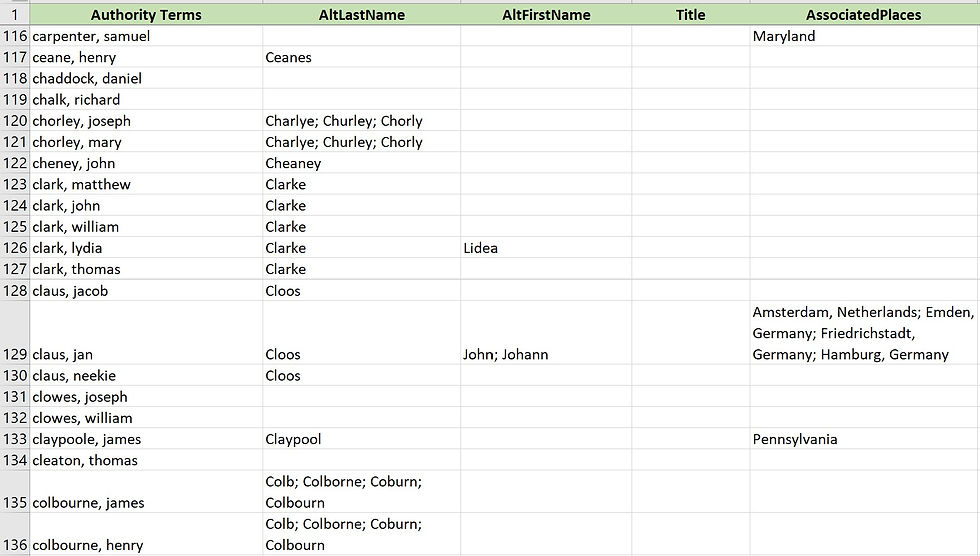
Once the name spellings and variations were confirmed, I then again filtered by color to import the established People Names standards into the proper sheet. Along with the metadata imported from the Key Words sheet, I added columns separating out associated name elements—alternative First and Last Names, as well as Title. Thus, the networks of correspondence and acquaintance within the Pemberton Papers now constitute a dataset with which we can test the database. [Figure 3] While not all goals established at the beginning of the semester were completed, this data set is one of many “further steps” taken this semester toward larger goals. Much of this semester was focused on establishing groundwork for the next—empowering other teams with knowledge and direction with which they will also make further steps.



Comments